About DeepSeek-R1
About DeepSeek-R1
A quick overview


Based on the abstract and introduction, this paper essentially proves that obtaining a post-training model solely through a pure reinforcement learning process is possible. Although R1-Zero exhibits poor readability and language mixing, it still demonstrates remarkable reasoning capabilities. The remaining question is how to address the abnormal outputs. The text underlined in red in the picture outlines their entire process.
Keyword:
- Pure RL.
- CoT, it is like gpt-o1.
- Group Relative Policy Optimization (GRPO), they adopt GRPO as the RL framework.
Worth noticing:
- Reward modeling
- Accuracy.
- Format. - format matters. (like the tag
</think>)
-
our distilled 14 B model outperforms state-of-the-art open-source QwQ-32 B-Preview.
- Their unsuccessful Attempts
- Process Reward Model
- Monte Carlo Tree Search
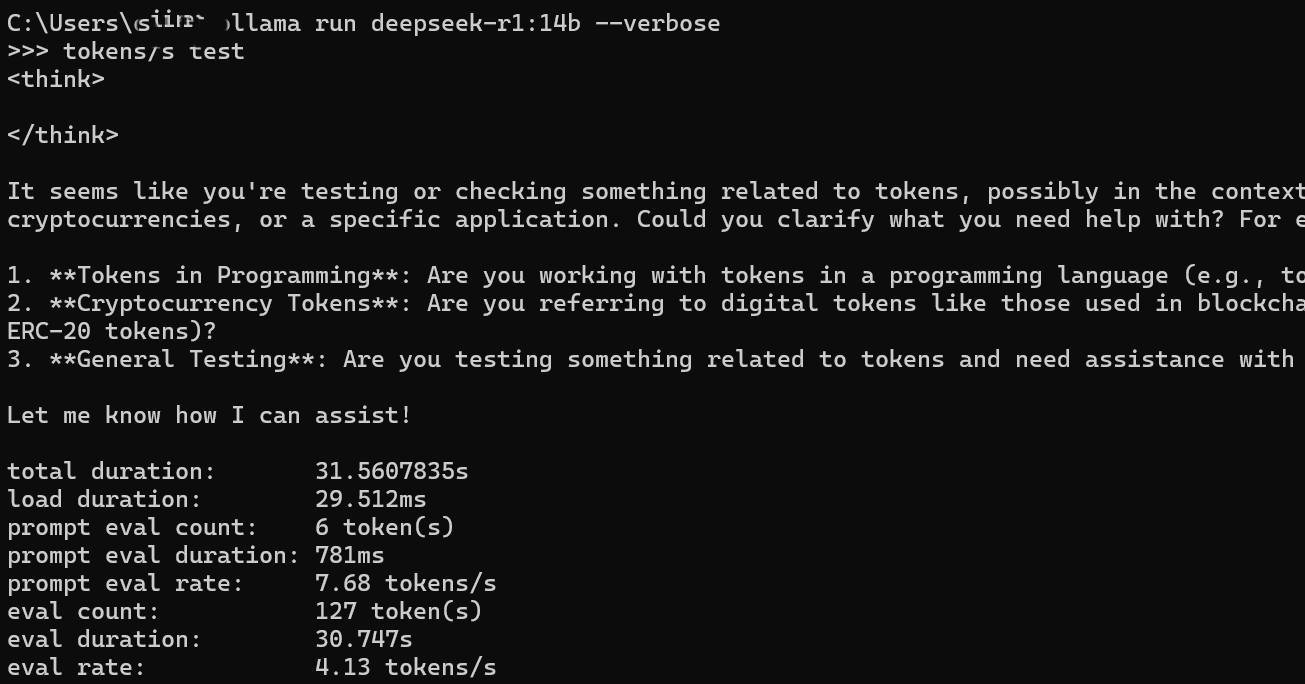
Run it on my device...
Running 8b model on M4 mac mini is practical, the number of token/s is about 20.
While it is around 7 on my Windows laptop without a graphics card.
As for the 14B model...