Agentic RAG
Agentic RAG
Recently, I have seen lots of posts and videos about agentic RAG.
Like,
, andI’m excited to kick off the first of our short courses focused on agents, starting with Building Agentic RAG with LlamaIndex, taught by @jerryjliu0, CEO of @llama_index.
— Andrew Ng (@AndrewYNg) May 8, 2024
This covers an important shift in RAG (retrieval augmented generation), in which rather than having the… pic.twitter.com/KwRvDEhENS
If you want to learn about building agentic RAG systems this weekend, then we recommend looking into this comprehensive blog/tutorial series by @Prince_krampah - starting with basic routing and function calling to multi-step reasoning over complex documents 🧠📑
— LlamaIndex 🦙 (@llama_index) June 8, 2024
Best of all, it… pic.twitter.com/YTx7MDu2X7

Basically, it is a combination of agent&RAG. Classic/Vanilla RAG works with vector store or knowledge graph in a cascade manner/one-shot query, while agentic RAG introduces agent reasoning loop into the process.
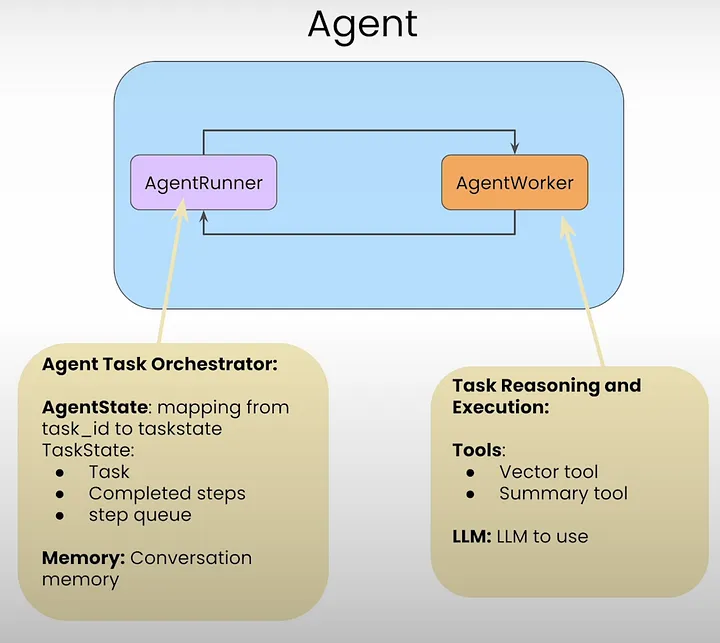
Specifically, agentic RAG is a framework that uses intelligent agents to improve information retrieval and generation. It involves a meta-agent coordinating document agents, each capable of understanding and summarizing their documents, to provide comprehensive answers to complex queries.
- Document Agents: Each document is associated with a document agent capable of answering questions and summarizing content within its own document.
- Meta-Agent: A top-level agent, known as the meta-agent, manages all the document agents. It orchestrates the process by deciding which document agent to use for a given query.
- Query Processing: The user’s query is processed by the meta-agent to determine the most relevant document agents.
- Information Retrieval: The selected document agents retrieve information from their respective documents.
- Synthesis: The meta-agent synthesizes the retrieved information to generate a comprehensive response.
In this case, there are two documents/papers.
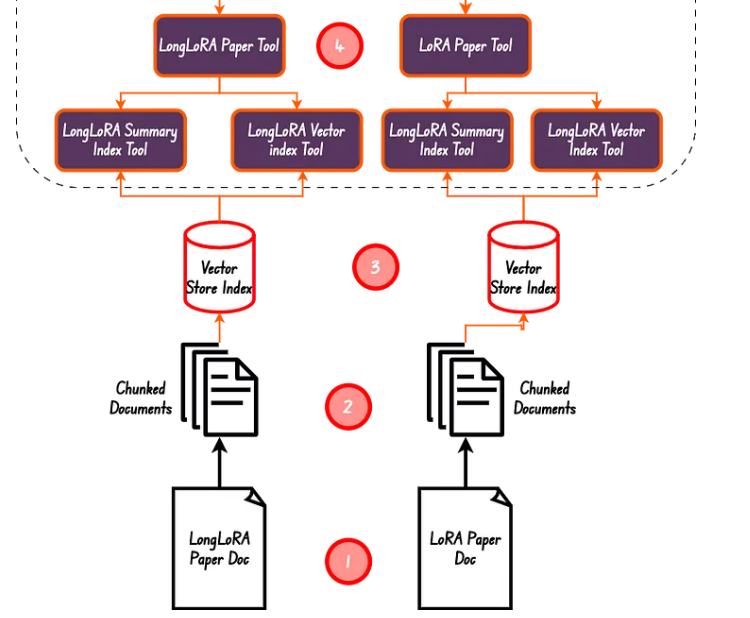
A simple example of creating vector query and summarizing tools for a doc. 👇
async def create_doc_tools(
document_fp: str,
doc_name: str,
verbose: bool = True,
) -> Tuple[QueryEngineTool, QueryEngineTool]:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_summary_query_engine_tool",
query_engine=summary_query_engine,
description=(
f"Useful for summarization questions related to the {doc_name}."
),
)
vector_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_vector_query_engine_tool",
query_engine=vector_query_engine,
description=(
f"Useful for retrieving specific context from the the {doc_name}."
),
)
return vector_tool, summary_tool