CLIP and variants
CLIP and variants
mindmap
root((CLIP))
Multimodal
Vision_Language_downstream_tasks
Image_Generation
CLIP_passo
VQGAN_CLIP
CLIP_Draw
Other_Domains
depth_CLIP_optical_flow
point_CLIP_3D
audio_CLIP_audio
Segmentation
Group_Vit
Lseg
Object_Detection
ViLD
GLIP_V1_V2
Video
Video_CLIP
CLIP4clip
Action_CLIPAll these papers:
- CLIP as a feature provider.
- CLIP as a teacher.
- CLIP as a method. (multi-modality contrast learning)
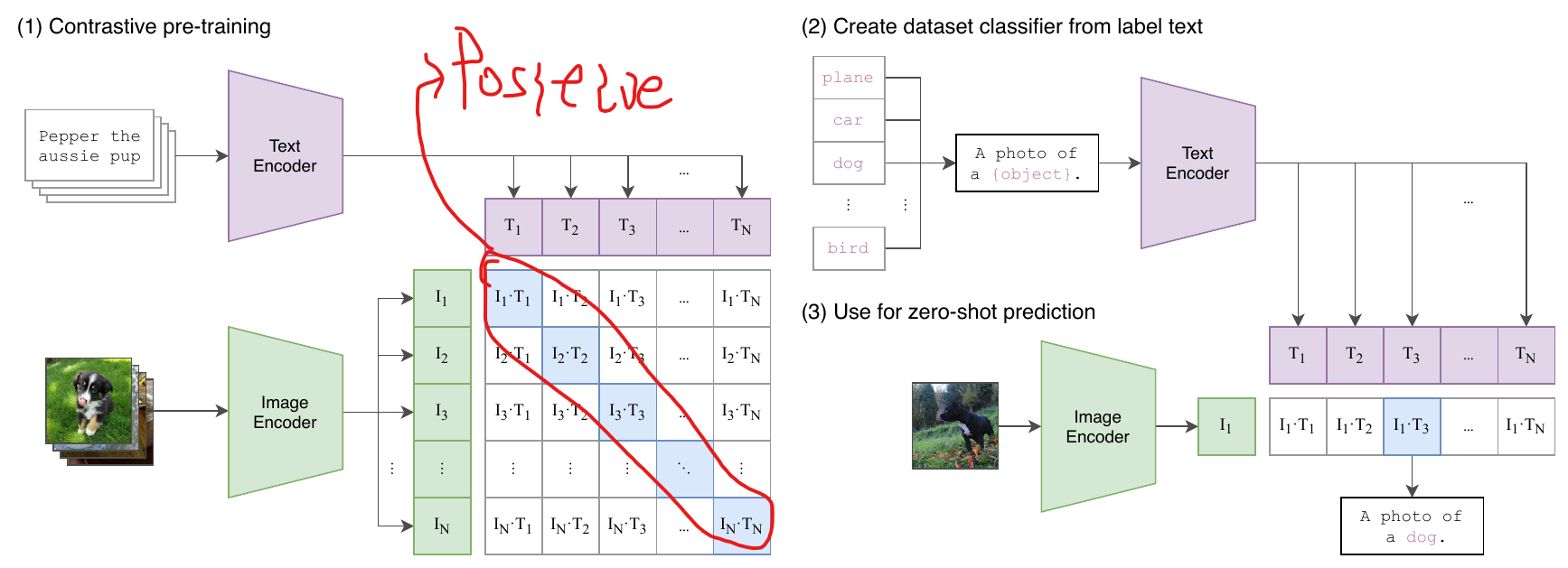
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
ViLD
Knowledge distillation
GLID
Vision grounding
Glidv 2 more tasks.
ClIPasso
cite 13, why CLIP robust.
siggraph 2022 best paper
sketching
CLIP4Clip
If you know the similarity between text and image, you can then do ranking matching retrieving.
Empirical study of how to utilize tempo information.
Simple way (mean pooling)/transformer/early fusion (tight type)
ActionClip
Prompt tuning adapter LoRA efficient fine tuning
Just like CLIP4Clip -- three way to convert image to video embedding.