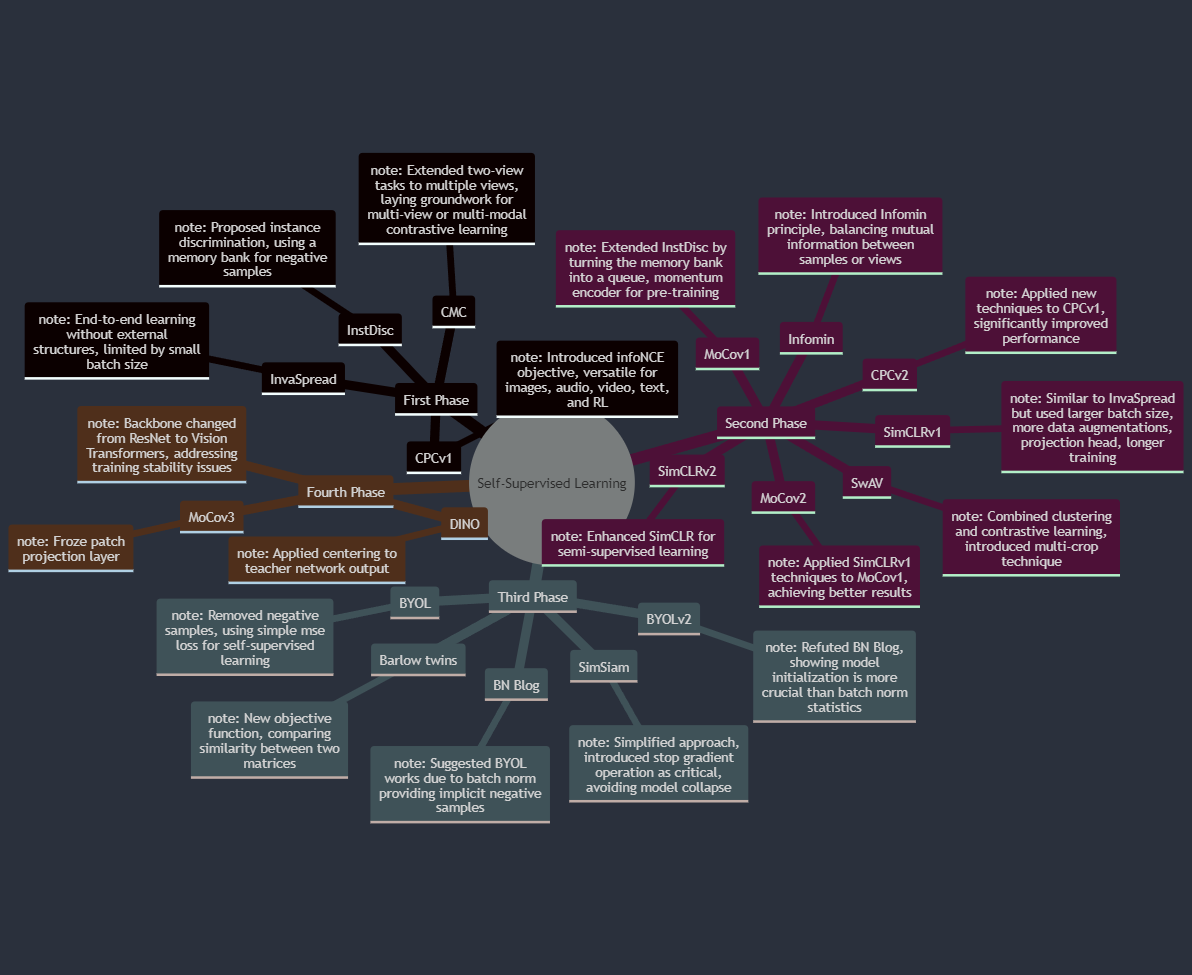
Contrastive learning in CV
mindmap
root((Self-Supervised Learning))
First Phase
InstDisc
note: Proposed instance discrimination, using a memory bank for negative samples
InvaSpread
note: End-to-end learning without external structures, limited by small batch size
CPCv1
note: Introduced infoNCE objective, versatile for images, audio, video, text, and RL
CMC
note: Extended two-view tasks to multiple views, laying groundwork for multi-view or multi-modal contrastive learning
Second Phase
MoCov1
note: Extended InstDisc by turning the memory bank into a queue, momentum encoder for pre-training
SimCLRv1
note: Similar to InvaSpread but used larger batch size, more data augmentations, projection head, longer training
CPCv2
note: Applied new techniques to CPCv1, significantly improved performance
Infomin
note: Introduced Infomin principle, balancing mutual information between samples or views
MoCov2
note: Applied SimCLRv1 techniques to MoCov1, achieving better results
SimCLRv2
note: Enhanced SimCLR for semi-supervised learning
SwAV
note: Combined clustering and contrastive learning, introduced multi-crop technique
Third Phase
BYOL
note: Removed negative samples, using simple mse loss for self-supervised learning
BN Blog
note: Suggested BYOL works due to batch norm providing implicit negative samples
BYOLv2
note: Refuted BN Blog, showing model initialization is more crucial than batch norm statistics
SimSiam
note: Simplified approach, introduced stop gradient operation as critical, avoiding model collapse
Barlow twins
note: New objective function, comparing similarity between two matrices
Fourth Phase
note: Backbone changed from ResNet to Vision Transformers, addressing training stability issues
MoCov3
note: Froze patch projection layer
DINO
note: Applied centering to teacher network output
- InstDisc: Inspired by supervised learning outcomes, it treats each image as a separate class and uses a convolutional neural network (CNN) to encode images into distinctive low-dimensional features. It employs contrastive learning with positive and negative samples, utilizing a memory bank to store negative samples due to their large number.
- InvaSpread: Considered a precursor to SimCLR, it uses mini-batch data as negative samples and performs end-to-end learning with an encoder.
- Contrastive Predictive Coding (CPC): A versatile structure that can handle audio, images, text, and reinforcement learning scenarios. It uses past inputs to predict future feature outputs in a sequence.
- Contrastive Multiview Coding (CMC): Aims to learn robust features invariant to different views, such as visual and auditory signals, by maximizing mutual information across different perspectives.
- Momentum Contrast (MoCo): Introduces a queue and a momentum encoder to form a large and consistent dictionary for better contrastive learning.
- A Simple Framework for Contrastive Learning of Visual Representations (SimCLR): Utilizes a large batch size and data augmentation to generate positive and negative samples for contrastive learning.
- Bootstrap Your Own Latent (BYOL): A self-supervised learning approach that does not rely on negative samples, avoiding model collapse through a unique training strategy.
- Exploring Simple Siamese Representation Learning (SimSiam): Achieves good results without negative samples, large batch sizes, or momentum encoders.
- Vision Transformers: The integration of Vision Transformers with self-supervised learning has led to methods like MoCov 3 and DINO, which explore the properties of Vision Transformers in a self-supervised setting.
The BN blog in the diagram: Understanding self-supervised and contrastive learning with "Bootstrap Your Own Latent" (BYOL) - imbue