DALL-E
DALL-E
-
DALL-E mini 本地运行。08:40
-
11:14 Timeline.

-
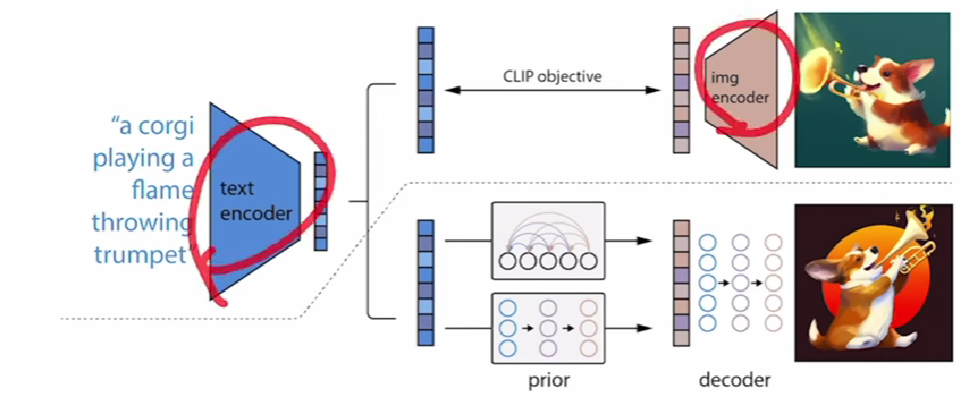
Hierarchical Text-Conditional Image Generation with CLIP Latents.12:35
-
Two-stage model: A prior -> generate a CLIP image embedding; A decoder -> generate an image based on the embedding. 16:31
-
Diffusion model 生成的图像多样性比 GAN 要好,但保真度不如 GAN fidelity,但近期使用 guidance 技术有所提高。17:57
-
生成 text-image pair 23:58
-
UNCLIP 27:17
-
Related work
- GAN 29:22
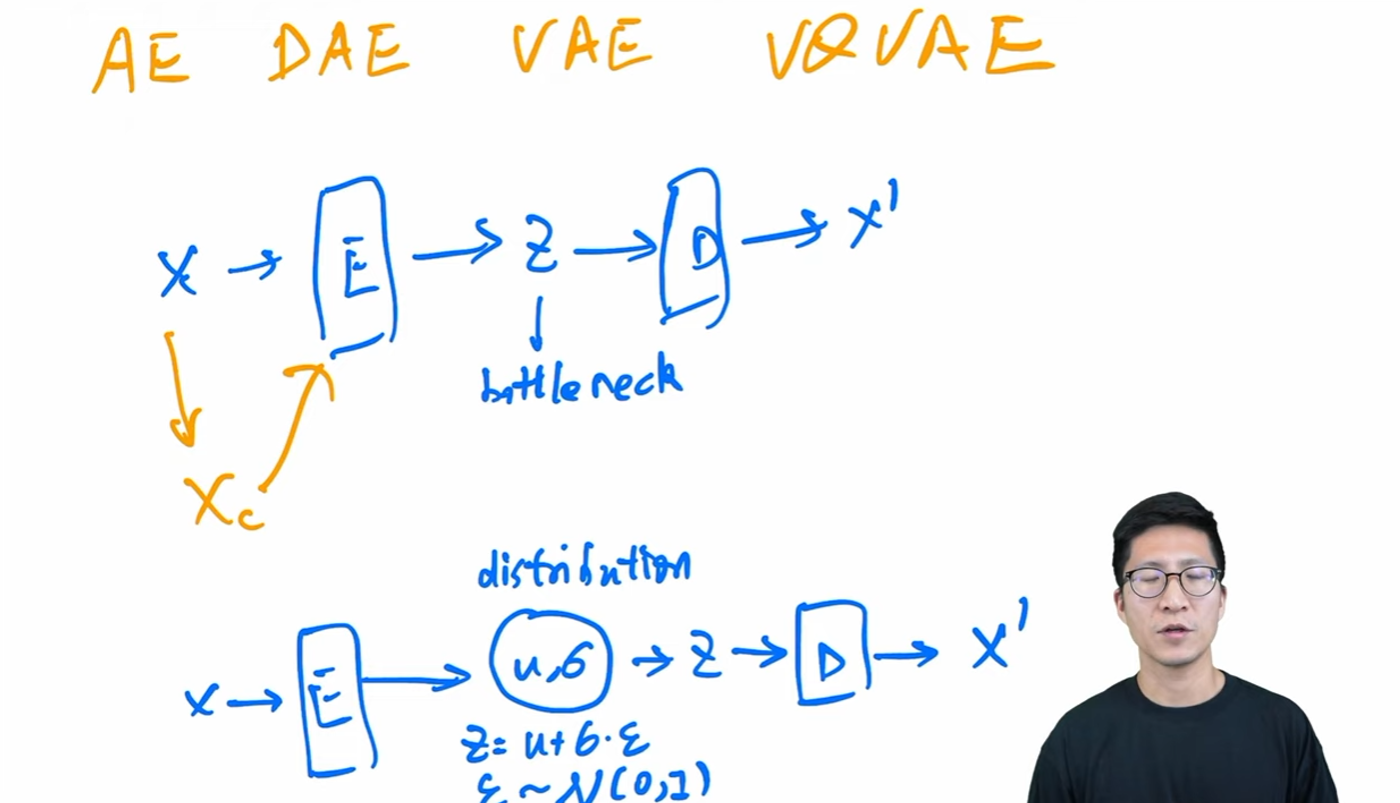
- VAE 与 DAE。VAE 与 auto-encoder 不同之处在于,auto-encoder 学习的是 bottleneck 特征,而 VAE 是通过学到特征预测一个 distribution,在采样生成特征(对应 bottleneck 特征)。 31:07
- VQVAE 使用
codebook代替采样过程,codebook中相当于标准化(量化)的特征,由codebook生成的z特征更容易优化 37:36。但没有了生成的过程随机采样,作为生成模型需要改进——VQVAE + TexT -> GPT -> result. 39:38。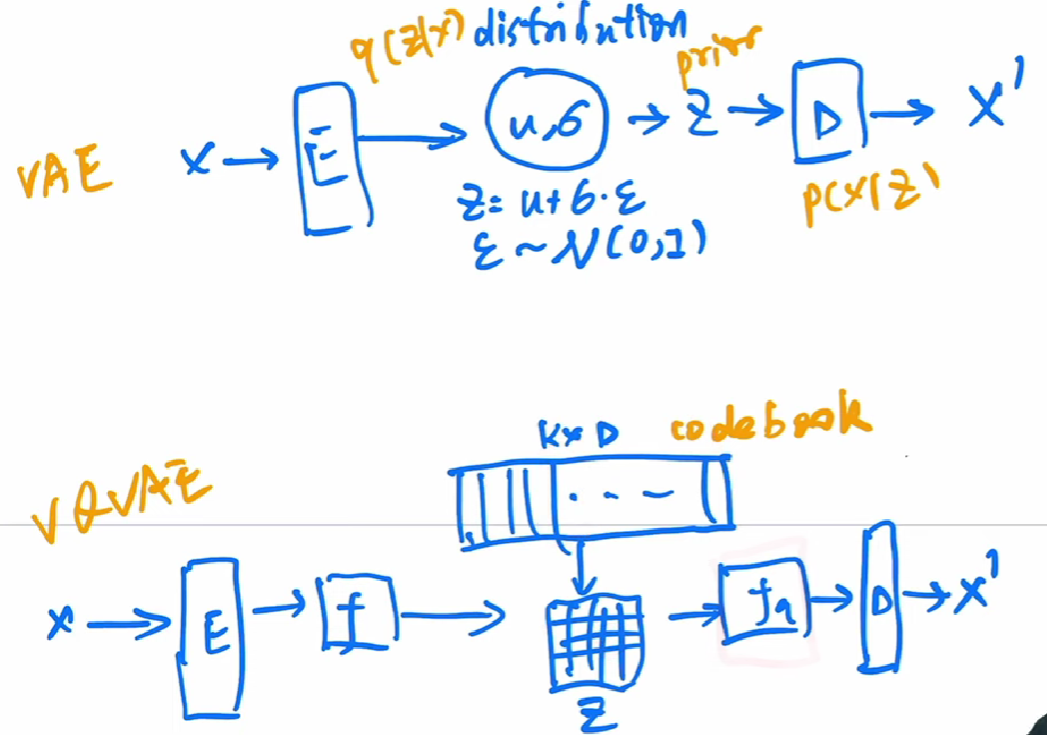
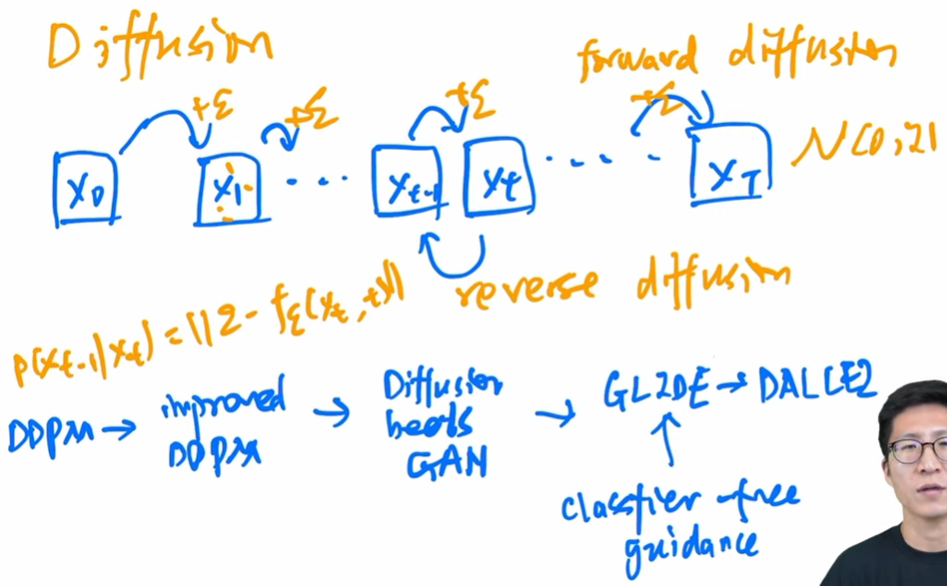
- Diffusion model. 这部分讲得很好:扩散模型 15 年已经提出,但到 DDPM 才真正优化到可用。DDPM 不预测扩散过程而预测噪声生成;噪声生成共享参数,因此需要增加过程的 index,告诉模型进行到了第几步;预测分布只要预测均值方差就行,甚至可以只要均值。 42:31
- end of 2020, Improved DDPM: 学方差,noise schedule 线性改为余弦,证明大模型牛。52:12
- Diffusion beats GAN: classifier guided diffusion, 同时训练一个分类器,告诉模型生成的图片更像某一个物体。也可以用其他特征进行引导。(必须要引入另一个条件模型)58:37
- GLIDE: classifer free guidance, 学习有条件和无条件生成的差距,进而无需条件也可更好。(训练更贵)01:00:42
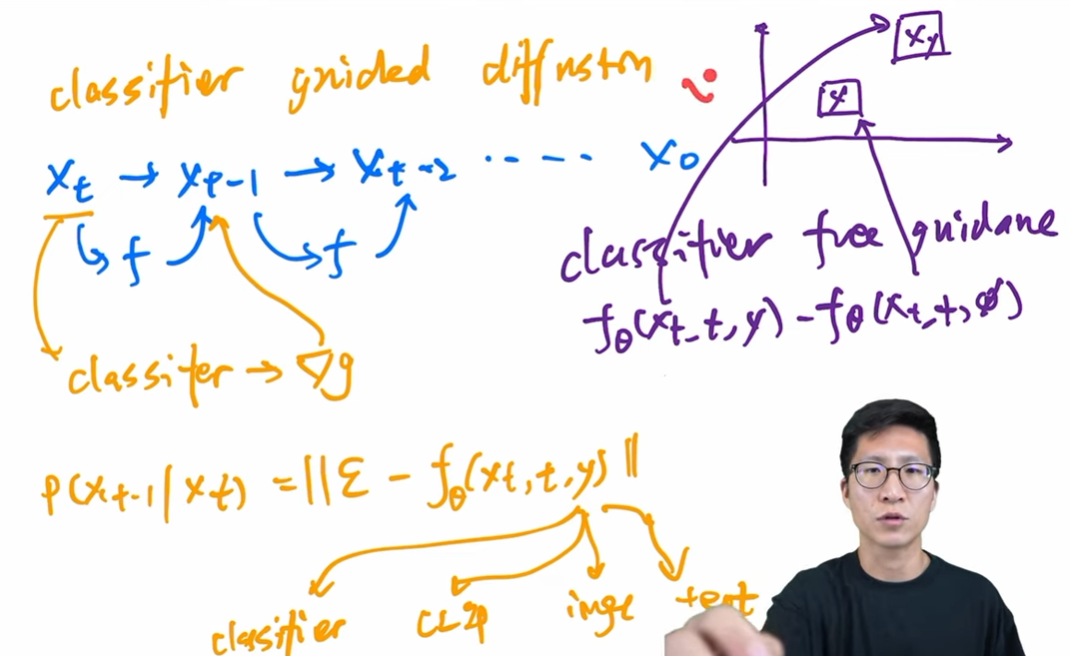
- DALL-E 2: 在 GLIDE 之上改进,增加 prior, 层级式等一系列技巧。01:01:30
-
上面提到的能用的技巧都用了。 01:05:21
-
主题方法讲完,一些观点总结。Scale matters: 其他都可以取舍。剩下的内容为实验等。 01:10:05
-
一些局限性。 01:17:48
-
为什么不能生成带文字的图片,可能是因为 BPE 编码:词根词缀。01:19:24 可以通过 DALLE-2 的黑话绕过 consorship.