GPT, GPT-2, GPT-3, GPT-4
GPT
- Credit to OpenAI. 2020 出圈。
- GPT-3 demo. 05:11
- 07:28
 4. GPT 选择的问题更大,更通用,更大,引用率并没有 BERT 高。 5. GPT 使用 Transformer decoder,有掩码:只能看到前面的词。21:22 6. BERT 与 GPT 的区别是 GPT 的目标函数更难,预测下一个词(预测未来)比预测中间的词更难(BERT 的 BLANK MASK)。技术路线 22:58 7. 子任务。26:26 8. 12-layer 768-dimension 与 BERT 相同。
4. GPT 选择的问题更大,更通用,更大,引用率并没有 BERT 高。 5. GPT 使用 Transformer decoder,有掩码:只能看到前面的词。21:22 6. BERT 与 GPT 的区别是 GPT 的目标函数更难,预测下一个词(预测未来)比预测中间的词更难(BERT 的 BLANK MASK)。技术路线 22:58 7. 子任务。26:26 8. 12-layer 768-dimension 与 BERT 相同。
GPT-2
- GPT 被 BERT 打败。
- 以 zero-shot 作为卖点。35:44
- Zero-shot can not use the mark that are used in GPT as specific token to help complish tasks. (such, [START]) 38:51. Therefore, PROMPT is needed.
- Using Reddit post with a karma threshold to generate dataset. 41:18
GPT-3: Language Models are Few-Shot Learners
- GPT-2 is creactive but the performance is not remarkable. So, GPT-3 is to conquer the problem remained. 46:41
- 175 billion parameters. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning. (large 10 x) 49:34 不算梯度。
- 63 p,actually a technical specification, not paper.
- 当前 pre-train + fine-tune 中存在的问题。53:20
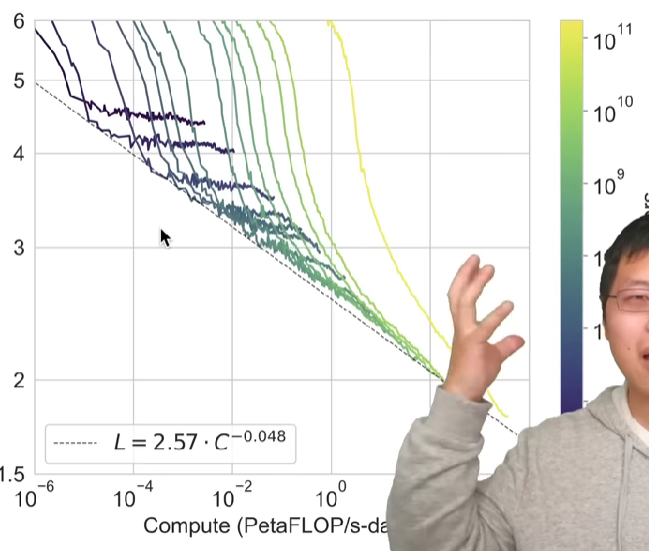
- 不做 gradient update 如何可能的?如图:

- 在 63 p 里,结构只有半页。😓 01:10:44
- Dataset use Common Crawl. GPT-2 don't do that for the poor quality of Common Crawl.
- Performance - compute. There is a best effort line. 01:19:55
GPT-4
- LLaMA 参数泄露。01:37
- Pytorch 2.0 发布。05:37
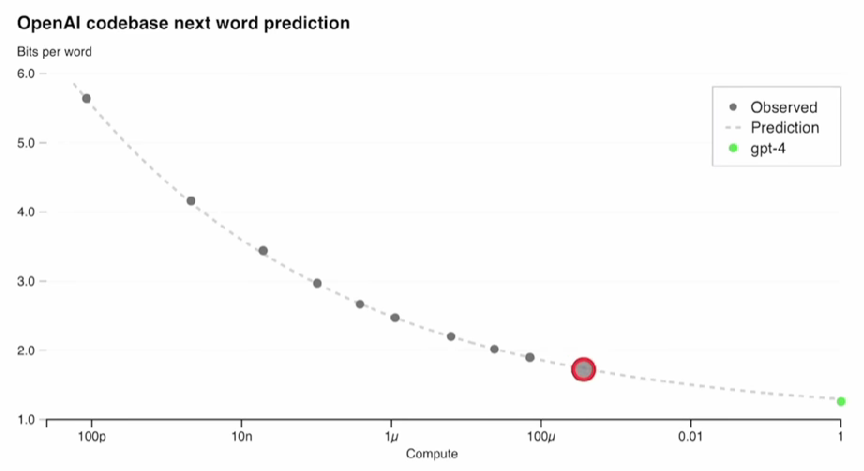
- Able to predict the model performance ahead of time. (According to the result of a smaller model.) 16:04
- 21:04
- 模型的能力是从预训练得到的,但是 RLHF 可以 fine-tune 模型的行为。(Reinforcement learning with human feedback ) 19:15
- Scaling 也是有新意的,会遇到很多前所未有的困难。 23:10
- Inverse scaling prize (大模型反而做得不好)。 25:24
- Steerability, 定义回答的语调和角色。01:16:16
- LeCun: Auto-Regressive LLMs are doomed. 01:15:57
- Bernhard Scholkopf's Twitter. 01:19:34