KAN network
KAN network
KANs have a fully-connected structure similar to MLPs
but instead of fixed activation functions on nodes (neurons), they have learnable activation functions on edges (weights).
This is the original KAN. n -> 2n -> 1
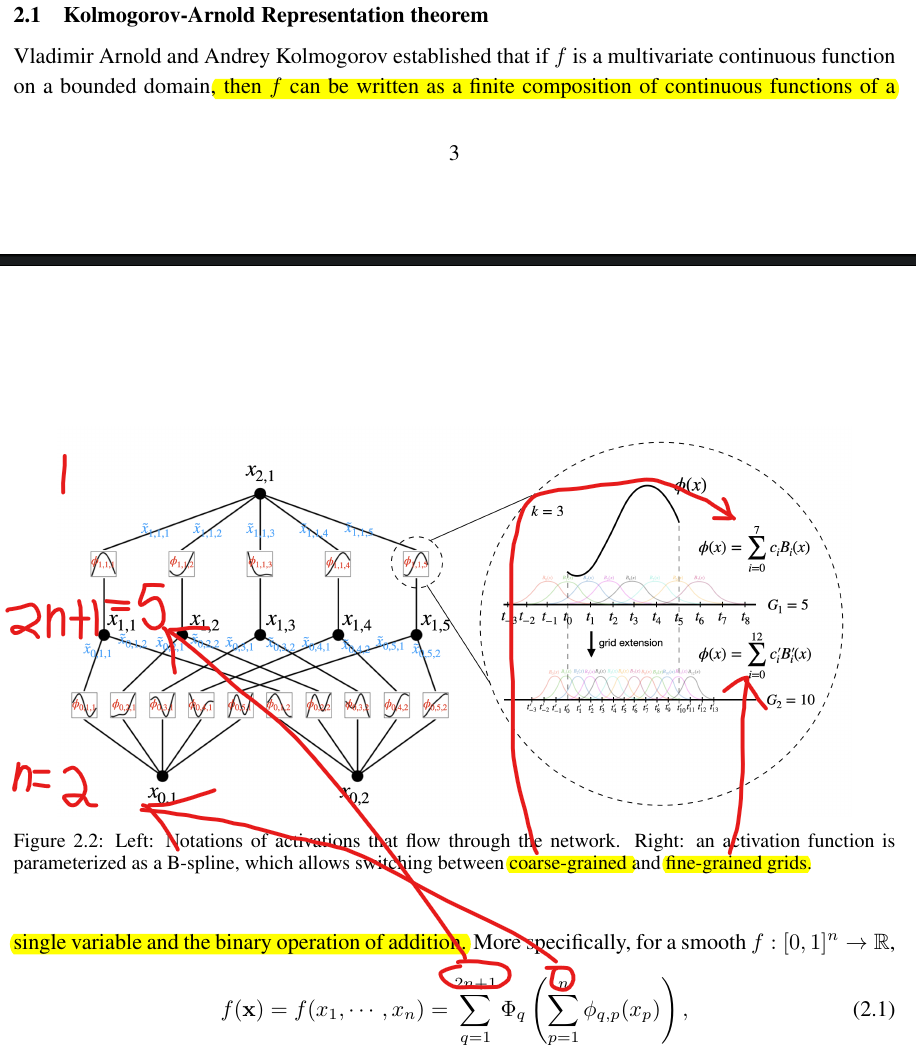
Then the author generalized the KAN network, make it deeper and flexible.
Why? why just stack.
No further explaining, but SIMPLY stacking.

Grid
This is kind like concept of resolution, a computation complexity and fidelity trade-off.

Activation function
It seems that the activation function choosing has no specific reason (as if it fit the previous assumption.), or I do not aware - I just skimmed the paper.
