Mamba
Mamba
[論文導讀] Mamba : 挑戰 Transformer 的新星 EP 1 Structured State Space Sequence Model (S 4) - YouTube
I have read this paper 4 months ago from X, and I knew this paper would go big. But I just skimmed the paper.
Why not A???
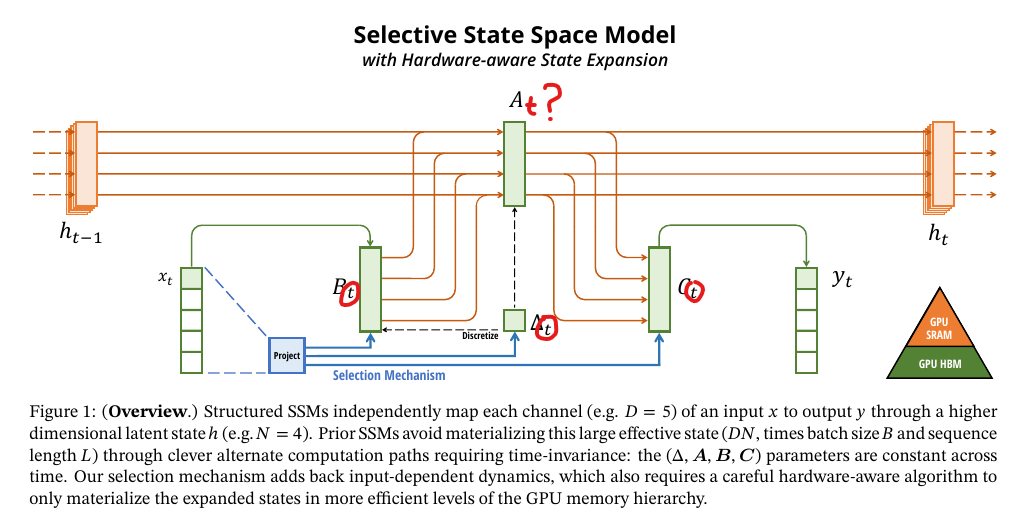
Mamba is a new class of models known as State Space Models (SSMs) that promise similar performance to Transformers with the ability to handle long sequence lengths efficiently.
- Efficiency: Mamba addresses the "quadratic bottleneck" of Transformers by enabling linear scaling in sequence length, making it feasible for sequences up to a million tokens and running up to 5 x faster.
- Performance: It achieves state-of-the-art results across various modalities, including language, audio, and genomics, even outperforming Transformers of the same size.
- State Space Model: Mamba uses a Control Theory-inspired SSM for communication between tokens, while retaining MLP-style projections for computation.
- Selective State: The model employs a selection mechanism that allows for context-dependent adjustments to the state, enhancing its ability to focus on or filter out inputs, which is crucial for managing long-term memory and context.
Mamba represents a significant advancement in sequence modeling, particularly for tasks requiring long-term memory and extensive context. It's a step towards more efficient and effective AI models capable of handling complex, long-range data.