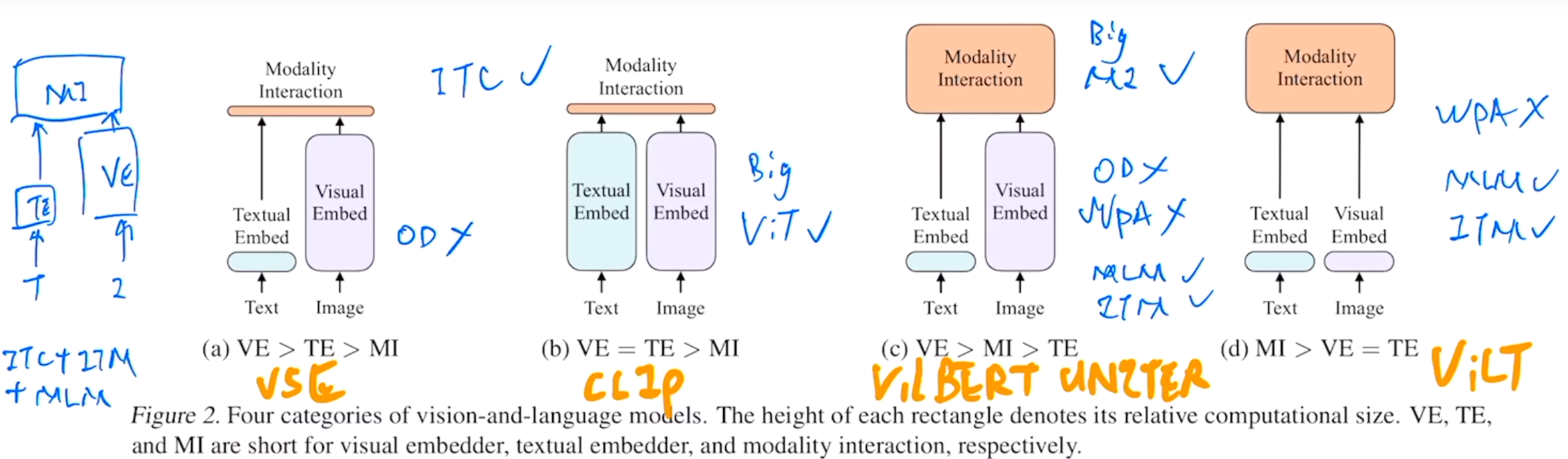
Figure 2. Four categories of vision-and-language models. The height of each rectangle denotes its relative computational size. VE, TE, and MI are short for visual embedder, textual embedder, and modality interaction, respectively
Category A: Models like VSE++ and SCAN, which use separate and heavy visual embedders compared to textual ones.
Category B: CLIP, which employs equally heavy transformer embedders for both visual and textual modalities.
Category C: Recent VLP models that utilize deep transformers for modality interaction but still rely on convolutional networks for visual embedding.
Category D: The proposed ViLT model, which simplifies the embedding of raw pixels and focuses computation on modality interactions.
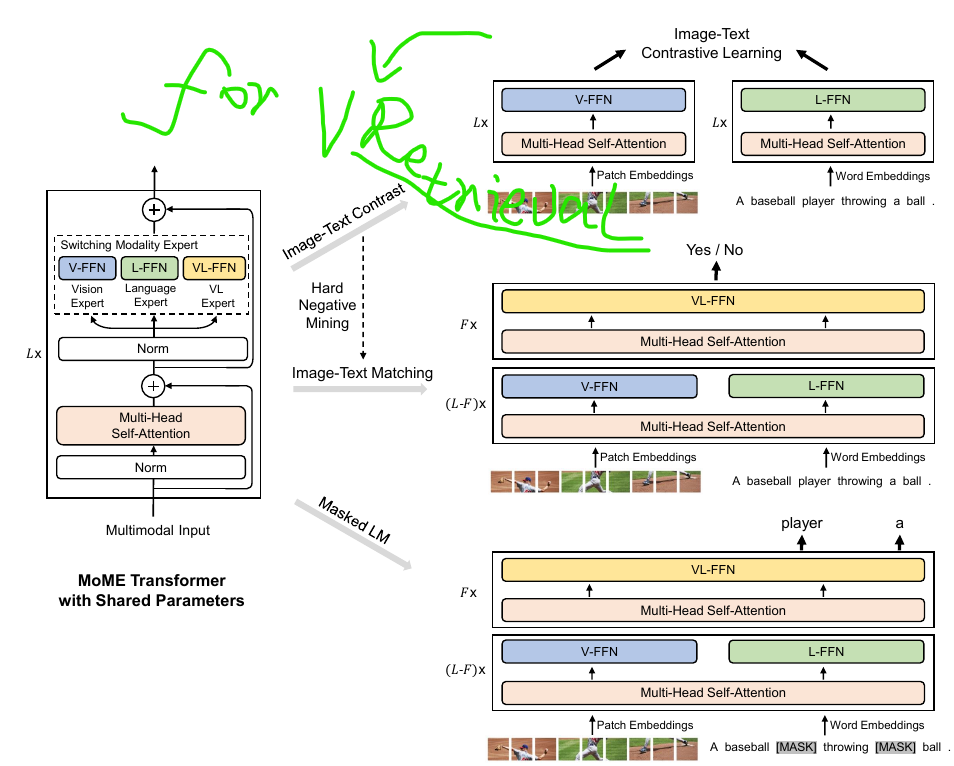
ViLT
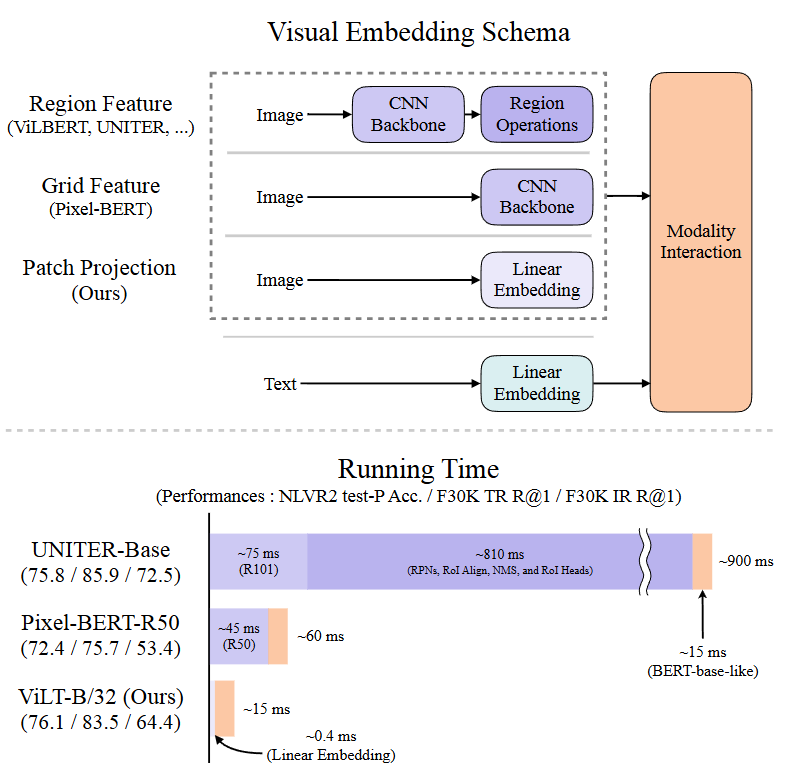
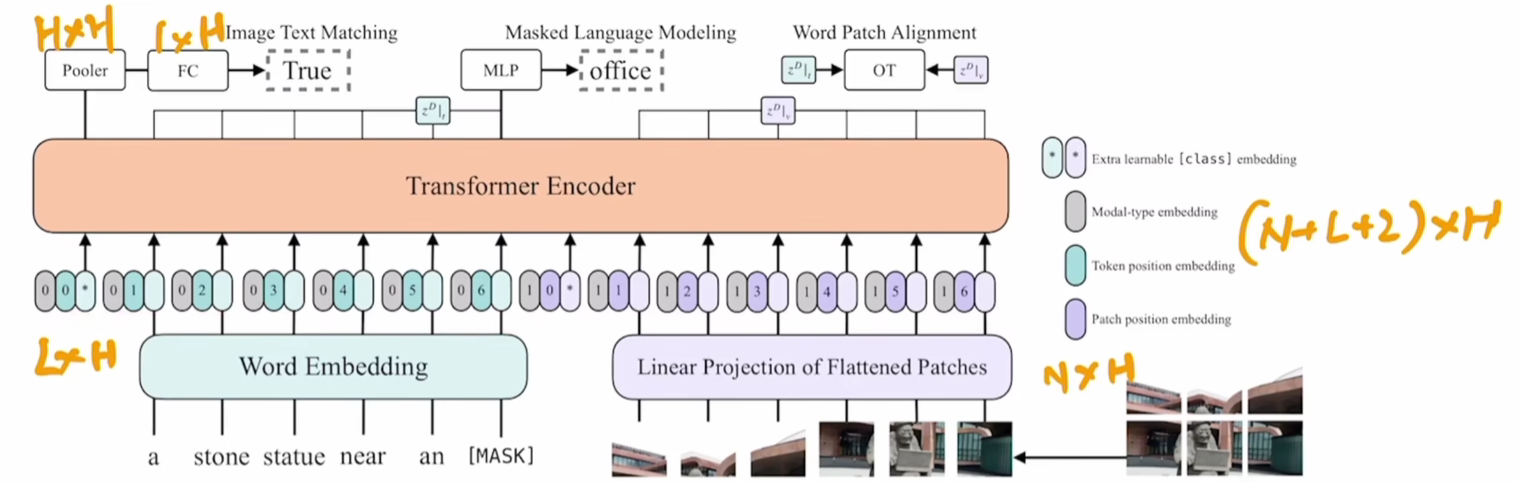
ViLT belongs to Category D; it removes region feature embed and adopts Patch projection.
ViLT runs fast, but the performance is actually not as well as Category C.
ALBEF
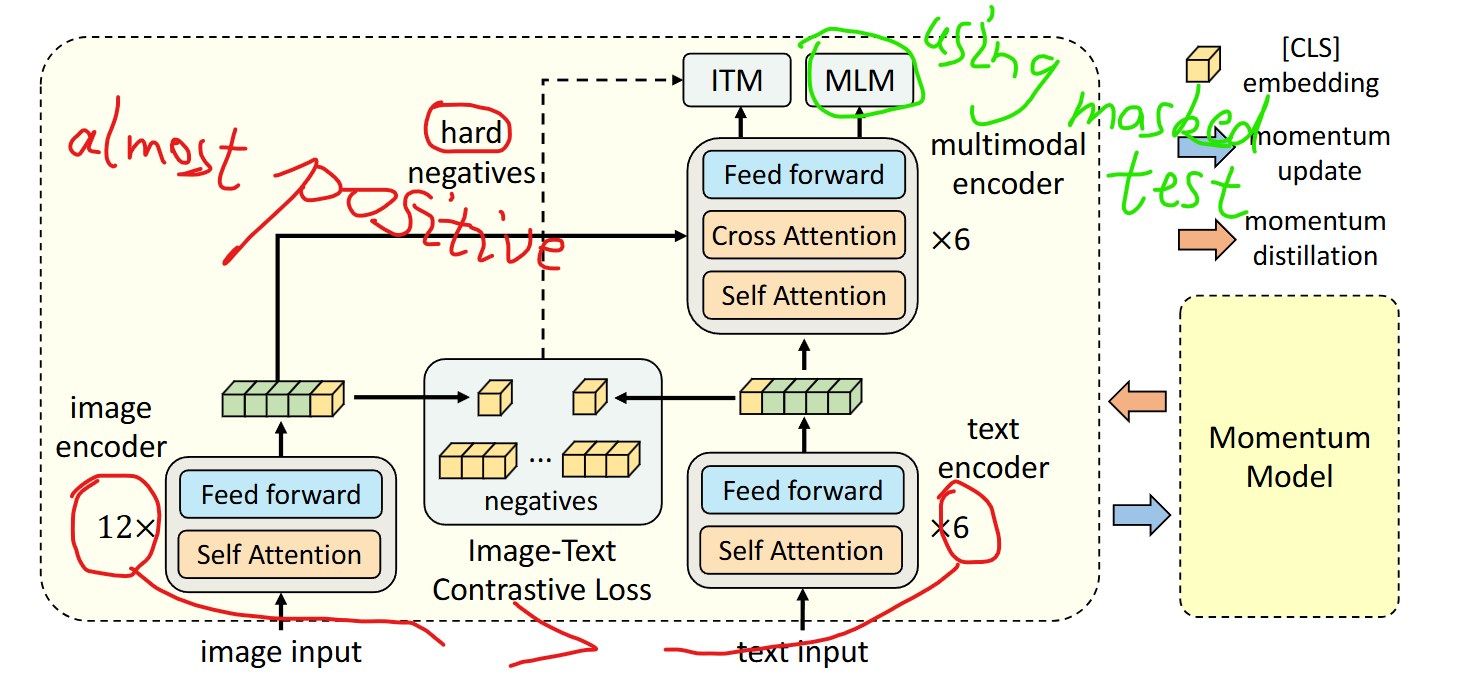
Unlike traditional methods that rely on pre-trained object detectors and high-resolution images, ALBEF uses a detector-free image encoder and a text encoder to independently process images and texts before fusing them with a multimodal encoder.
Momentum Distillation (MoD): A self-training method that uses pseudo-targets generated by a momentum model to improve learning from noisy web data.
During training, we keep a momentum version of the model by taking the moving-average of its parameters.
the one hot label is not good enough -- some candidates are even better than the ground truth, so ALBEF adopted MoD to generate a softmax score.
Image-Text Contrastive Learning (ITC): This objective focuses on aligning the image and text features before fusion by learning a similarity function. It uses a contrastive loss to ensure that corresponding image-text pairs have higher similarity scores compared to non-matching pairs.
Masked Language Modeling (MLM): Similar to the approach used in BERT, this objective predicts masked words in a sentence using both the image and the contextual text. It helps the model to understand the context and content of the images and texts better.
Image-Text Matching (ITM): This task determines whether an image and text pair match or not. It uses the multimodal encoder’s output to predict the probability of a match. The paper also introduces a strategy to sample hard negatives for ITM without additional computational cost.
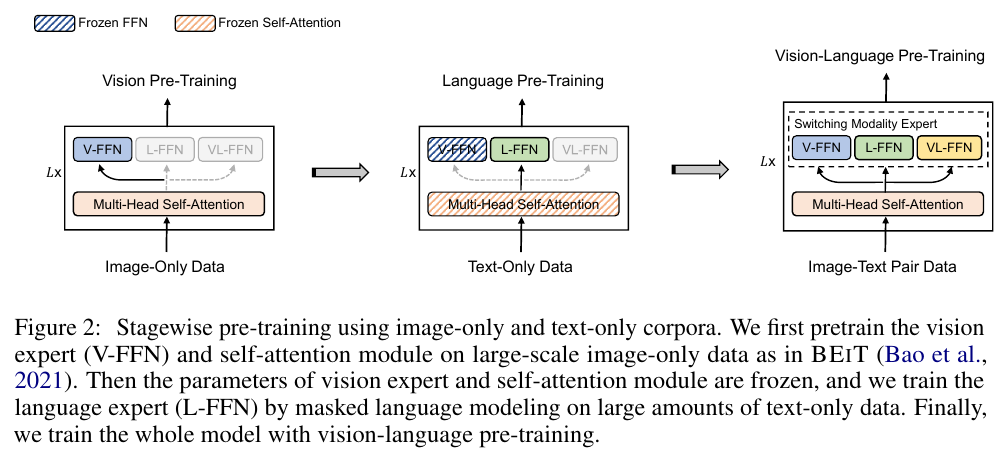
VLMo
Each paradigm has its pros and cons, so naturally they proposed MoME.
Transformer block does not have much inductive bias, so it can adapt to multiple modalities.
At that time, LAION dataset, WIT of Clip, etc. was not released; another benefit is that MoMe can utilize the single modality data to train the model.
Loss: same as ALBEF
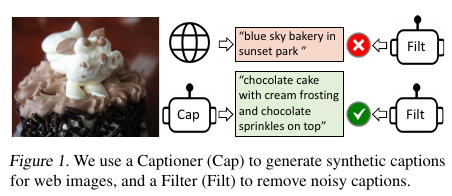
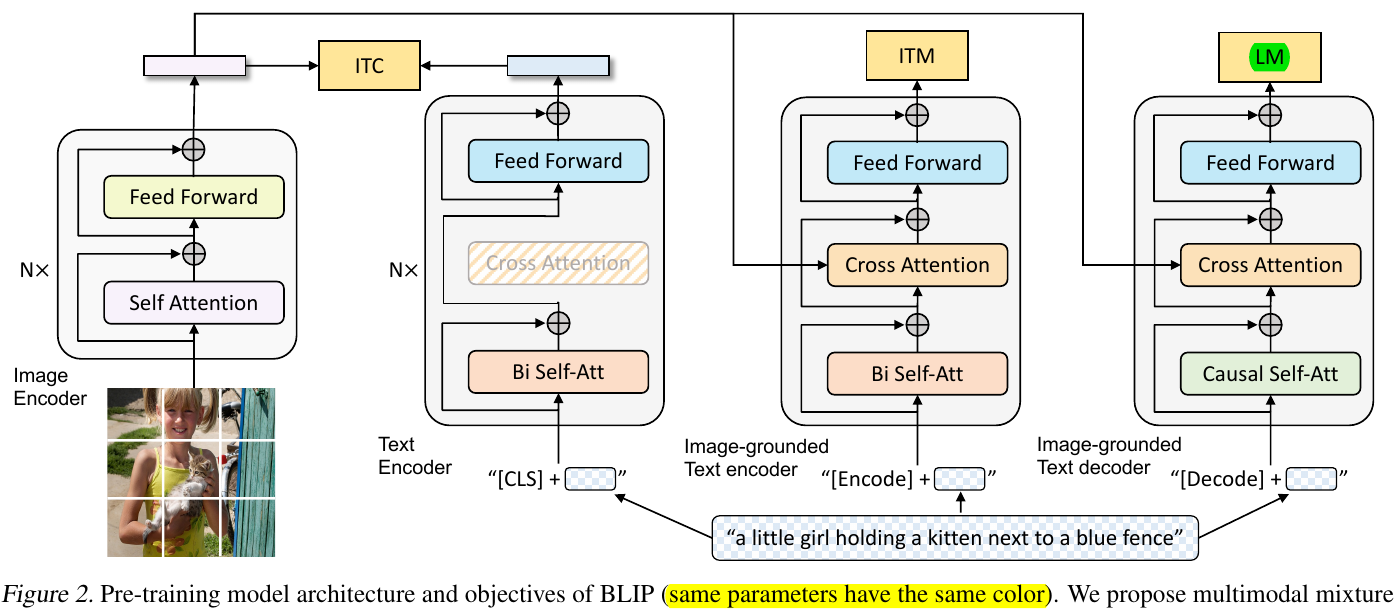
BLIP
Also Salesforce Research like ALBEF
BLIP: Language-Image Pre-training for Vision-Language Understanding and Generation
Bootstrapping:
Generate new cap to substitute the wrong alt text.
Unified:
Contrast with VLMo, sharing parameters, a extra decoder.
Referring to the decoder, language modeling (LM) loss and causal self-att are reasonable.
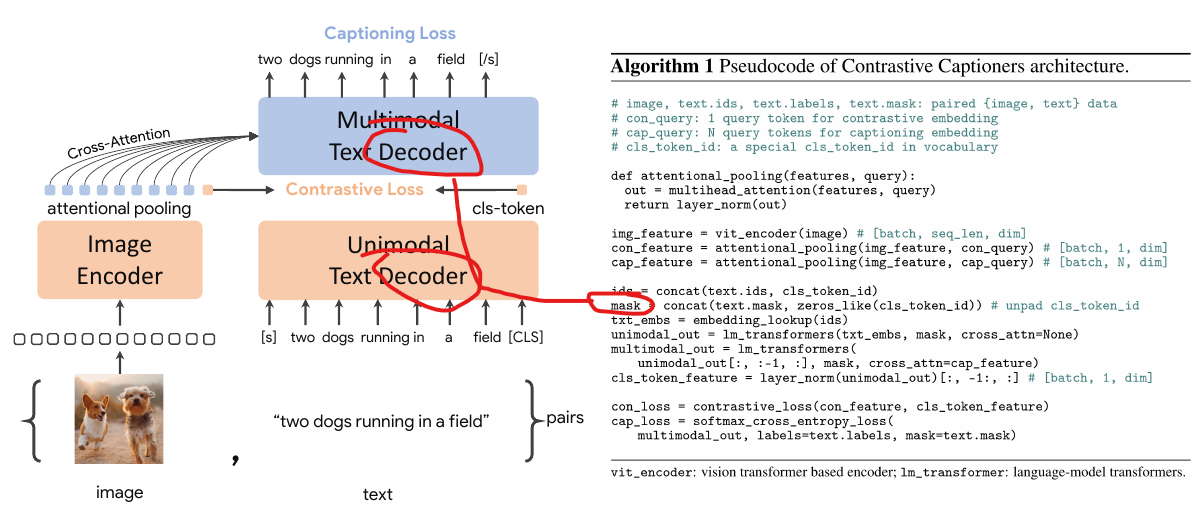
Coca
Images used attentional pooling, which was effective in the experiments of this paper.
The ITM loss was removed to speed up training. Originally, the text needed to be forwarded 2-3 times, but after removing the ITM loss, only one forward pass is needed. In ALBEF, ITM requires the complete text, while MLM requires masking, so there are two inputs. In BLIP, ITC is done once, ITM is done separately because a new module is inserted in the text model, and LM is done separately again because it uses both a new module and causal self-attention. In CoCa, to complete the captioning loss and ITC loss, only one forward pass is needed. In GPT, placing the cls-token at the end allows for a global representation to be obtained for the ITC loss.
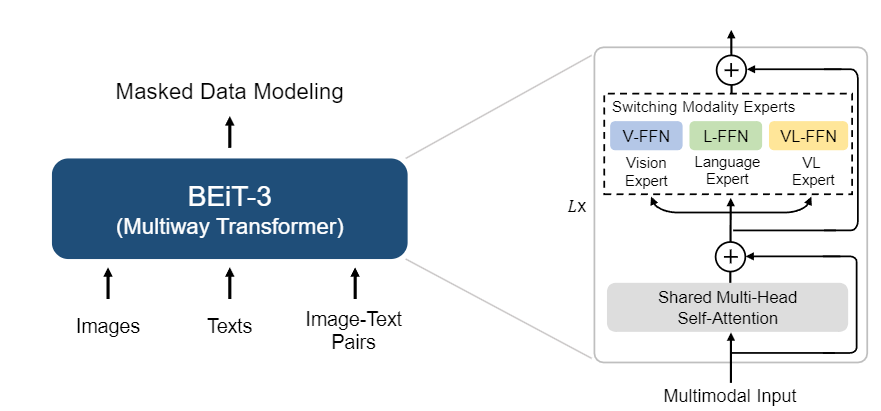
BeiTv3
Image as a Foreign Language
Same structure as VLMo.
Only one loss.
Mask anything.
Backbone Architecture: This involves the design of the underlying network that supports both vision and language tasks. A unified architecture allows for seamless integration and processing of multimodal data.
Pretraining Task: The tasks used during pretraining are crucial. They should be designed in a way that the model can learn generalizable features from both images and text that can be applied to various downstream tasks.
Model Scaling Up: This refers to increasing the size and capacity of the model to handle more complex tasks and larger datasets, which can lead to better performance and generalization.
Llava
Multimodal Data: They introduce a method to generate multimodal language-image instruction-following data using GPT-4.
Large Multimodal Model: Development of LLaVA, a large multimodal model that combines a vision encoder with a language model, fine-tuned on the generated data.