Part of my slide on vision-language models
Slide 3

So
Now we use Large Language Models, like GPT series, to solve various tasks, but it is not a new idea.
This is a paper from twenty-eighteen. In this paper, every task is regarded as a question-answering task. The term question' today is called prompt'.
And this paper is not the first paper to propose the concept either. In twenty-fifteen, there is already a paper, named `Ask Me Anything', mentioned making Large Language Model to be a generalist.
Computer Vision community also draws inspiration from the trend of Task-agnostic Objectives in NLP.
Slide 4
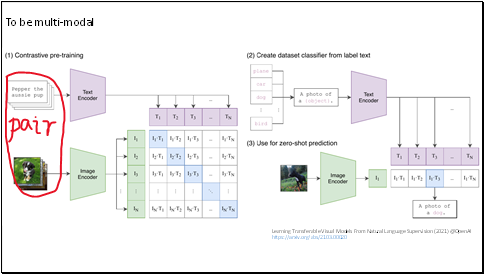
A famous work is CLIP from OpenAI.
Traditional computer vision systems are trained to predict a fixed set of predetermined object categories.
CLIP uses natural language to reference an open set of visual concepts. They just take a simple pre-training task of predicting which caption goes with which image.
There are many available image-text pairs, so the labeling job is not necessary.
Slide 5
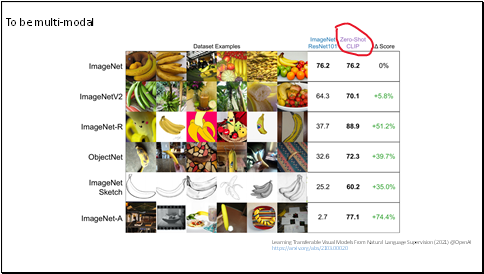
And learning from natural language has another benefit.
It doesn't "just" learn an image representation but also connects that representation to language which enables flexible zero-shot transfer.
This is distribution shift for bananas.
It shows that Zero-shot CLIP is much more robust to distribution shift than standard ImageNet models.
It is good news for the noisy data. Like the historical material with flicker, scratches, and so on.
Slide 6
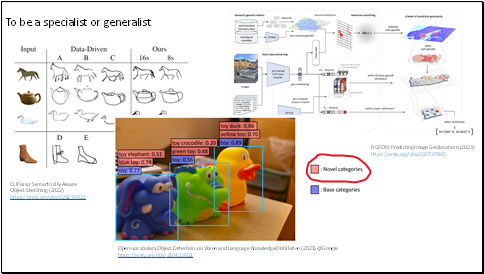
Following the paradigm that uses natural language as a visual reasoning guide, many amazing works on downstream tasks have been proposed.
Such as, CLIPasso: Semantically-Aware Object Sketching, or, predict image geolocation. Or open-vocabulary object detection.
You can see in the open-vocabulary object detection, the red labels are novel categories. The traditional object detection model will only give the predefined label, `toy'.
Besides these, there are many other works, like retrieving, captioning, grounding.
Slide 7
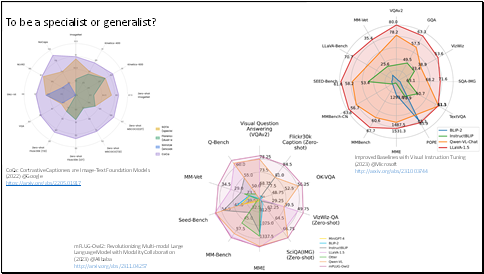
In recent months, the Multi-modal Large Language Model pre-trained by big companies with instruction-tuning have achieved stunning results.
Instruction-tuning in these models is just like the open question-answering with multi-modal inputs, which make these modal can handle different tasks, even the tasks they have never seen.
Recently, the authors like to draw this kind of diagrams, to show that their methods are better than any other state-of-the-art methods in any tasks and datasets.
And new bigger models keep wrapping the old ones with new scores, in the polygon, like the spider webs.
Slide 8
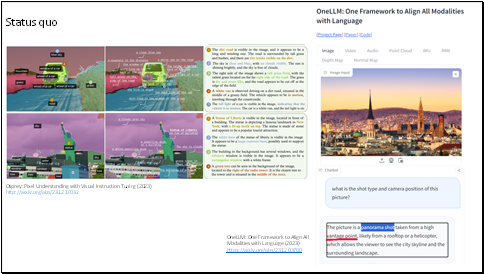
And the Multimodal large language models (MLLMs) have achieved impressive general-purpose vision-language capabilities through visual instruction tuning.
Most visual reasoning task can be well addressed. Like analyzing the shot type of the photograph. Semantic segmentation. And give detailed description of the image.
But the problem is that these models are too big. It is almost impossible to fine-tune these models in an end-to-end manner./ full fine-tune.
Slide 9

The large-scale pre-trained foundation models already can generate great multimodal embeddings, and fine-tuning these models most likely results in,
* over-fit.
* catastrophic forgetting. It means, (lost the general purpose capabilities/the ability of domain transfer/robustness)
Not mention that it would be extremely costly to fine-tune these models.
Thus, currently, a more practical way is to introduce a learnable interface to make the foundation model adapt better to the downstream tasks, which is called PARAMETER-EFFICIENT FINE-TUNING.
It is currently the mainstream, but these methods are not new.
They are learned from NLP community.
Slide 10
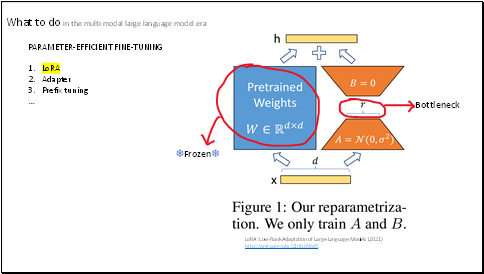
For example,
The LoRA method freeze the pretrained weights and only update the gradients of A and B, two linear projections.
Then add the result to the original network.
Slide 11
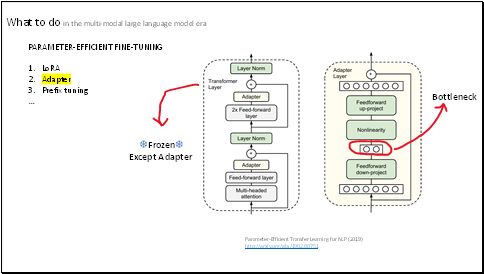
This is the architecture of the adapter module and its integration with the Transformer.
The adapter way is very flexible, and it can be added to anywhere.
Slide 12
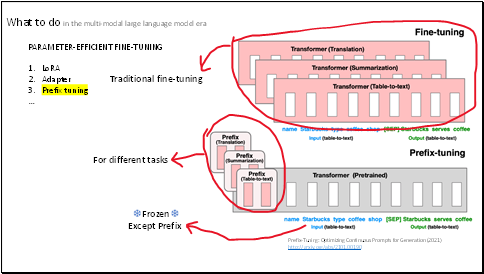
And the prefix-tuning, which freezes the Transformer parameters and only optimizes the prefix (the red blocks in the picture). This makes prefix-tuning||||modular and space-efficient.
Since today both NLP and CV communities prefer to use transformer as the backbone network, this is very useful.
And there are other similar methods, but the idea is all to make a plug-and-play learnable interface. Train the plugin not the whole network.
Slide 13
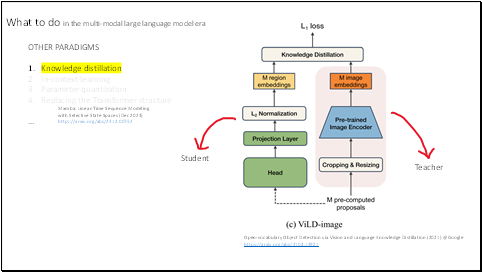
There are many other paradigms in the multi-modal large language model era.
Like knowledge distillation, using the large model as a teacher to get a smaller student network.
And so on. I won't present them all considering the time.
I won't say/not sure which is the best way to complete the vision-language tasks on historical images or films.
But utilizing the currently advanced foundation models, and doing some PARAMETER-EFFICIENT tuning is a practical, promising and popular research approach.
And it is currently how most image-language joint task have been done. It's a hotspot.
That's all.
Thank you for listening.
Slide 14
