Reducing cost and improve performance while using LLM
Reducing cost and improving performance while using LLM
Prompt Adaptation
We don't need all previous context when asking new question.
LLM Approximation
Completion cache: using the answer generated before.
LLM cascade

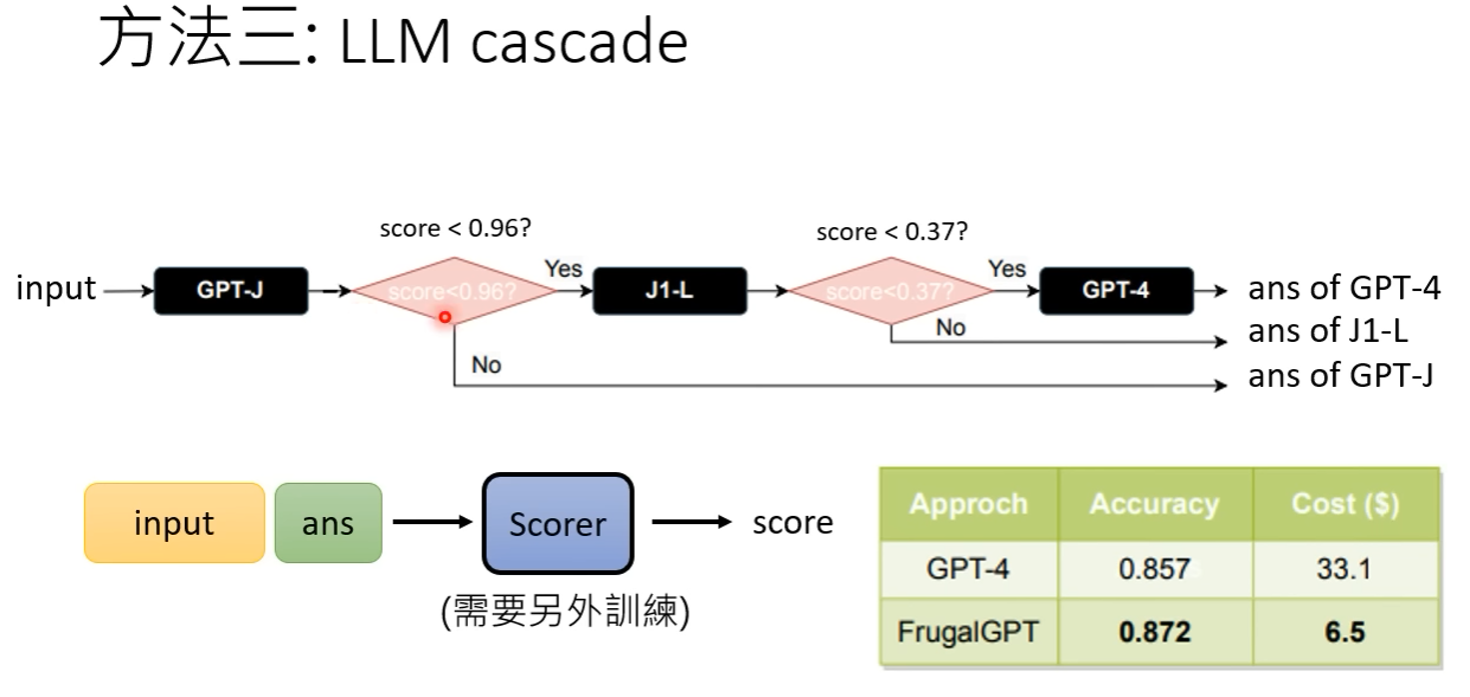
In this paper, the first two methods are merely concepts and the focus is on the third idea, LLM cascade.