Stable diffusion
Stable Diffusion
- 3 modular:01:50
- Text Encoder
- Generation Model: take noise vector as input.
- Decoder
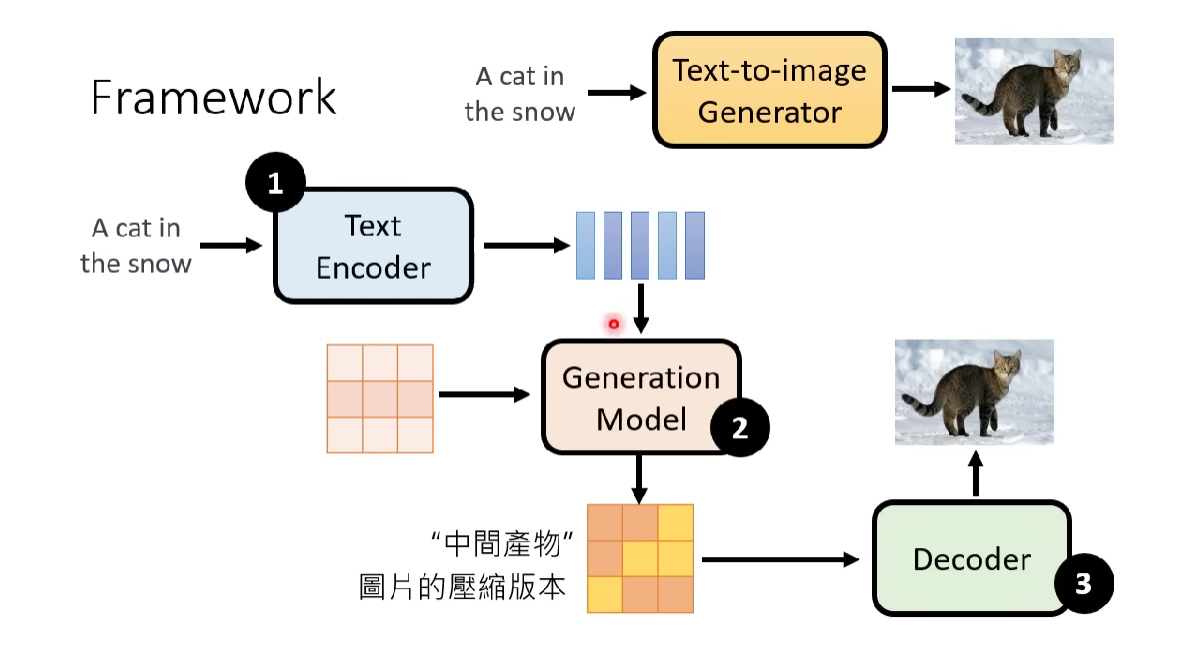
- DALL-E: component 2 can be repalced with Autoregressive Model to generate low quality/ppi/compressed version.03:11
- Text Encoder: GPT, BERT(too old). 文字 Encoder 比 Diffusion Modular 大小对效果影响更大。06:18
- FID, 算两组 Gaussians,测距离衡量。进而衡量生成效果。09:09
- Contrastive Language-lmage Pre-Training(CLIP): 使相关文字图片距离近,反之距离远。11:01
- Decoder 训练的两种情况:超分辨率或 En-Decoder。第二种情况在 latent representation 上加 noise。 13:20
- Midjourney 每次把 latent representation
decode, 所以可以看出过程。18:48