In practical applications, the annotation cost for many tasks is high, making it difficult to obtain sufficient training data. In such cases, transfer learning can be used. Suppose A and B are two related tasks. If task A has abundant training data, we can transfer some of the generalized knowledge learned from task A to task B. Transfer learning has several categories, including domain adaptation and domain generalization12345.
The paradigm of transfer learning in LLMs is pre-trained on massive data (multi-task learning or making the multi-task data into a unified form) and fine-tuned for specific tasks.
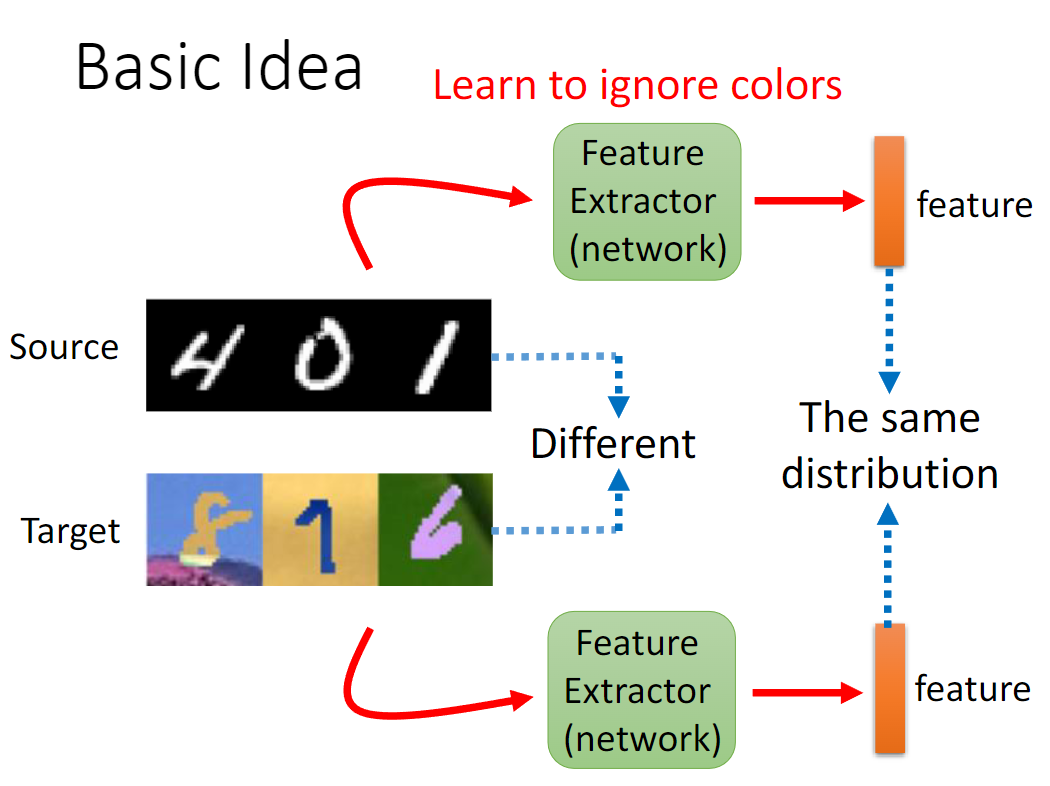
Domain adaptation deals with scenarios where we have a source domain (A) and a target domain (B). The goal is to train a model using data from the source domain and make it perform well on the target domain, even though labeled data from the target domain is scarce or unavailable.
A basic idea for domain adaptation is to train a feature extractor to eliminate the different part and keep the collective part/the essence of the source and target domain.
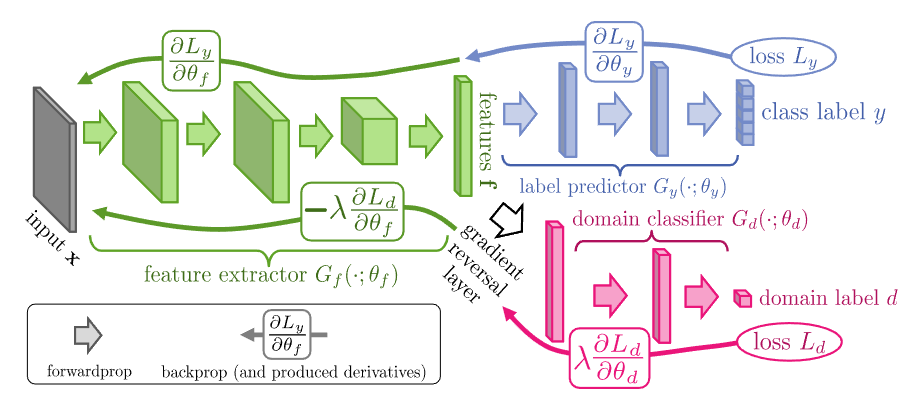
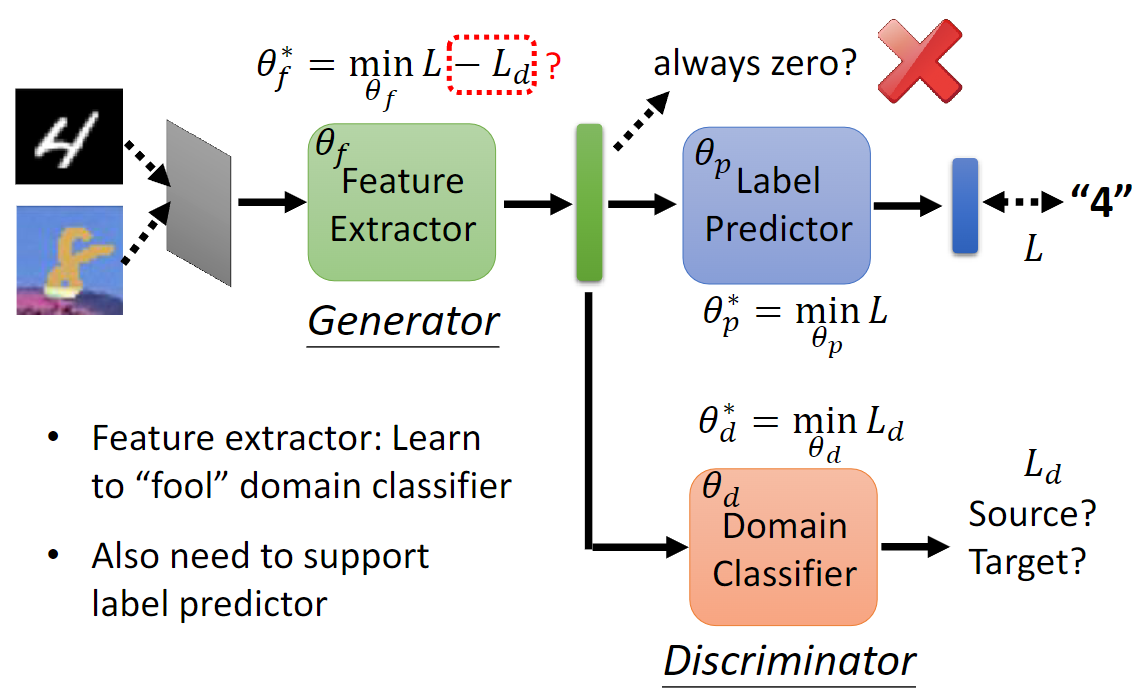
The problem is that we want the domain classifier to split the data of two domain and meanwhile the feature extractor to get the collective feature. It seems a little tricky.
Accelerating Deep Unsupervised Domain Adaptation with Transfer Channel Pruning IJCNN
Adversarial Adaptation of Scene Graph Models for Understanding Civic Issues WWW2019
Cross-Dataset Adaptation for Visual Question Answering CVPR2018
Cross-domain fault diagnosis through optimal transport for a CSTR process DYCOPS2022Code
Domain generalization/Learn a domain-agnostic model
Domain generalization focuses on a more challenging setting. Here, we have access to multiple related domains during training (e.g., sketches, cartoons, real images), but the goal is to build a model that generalizes well to unseen testing domains.